
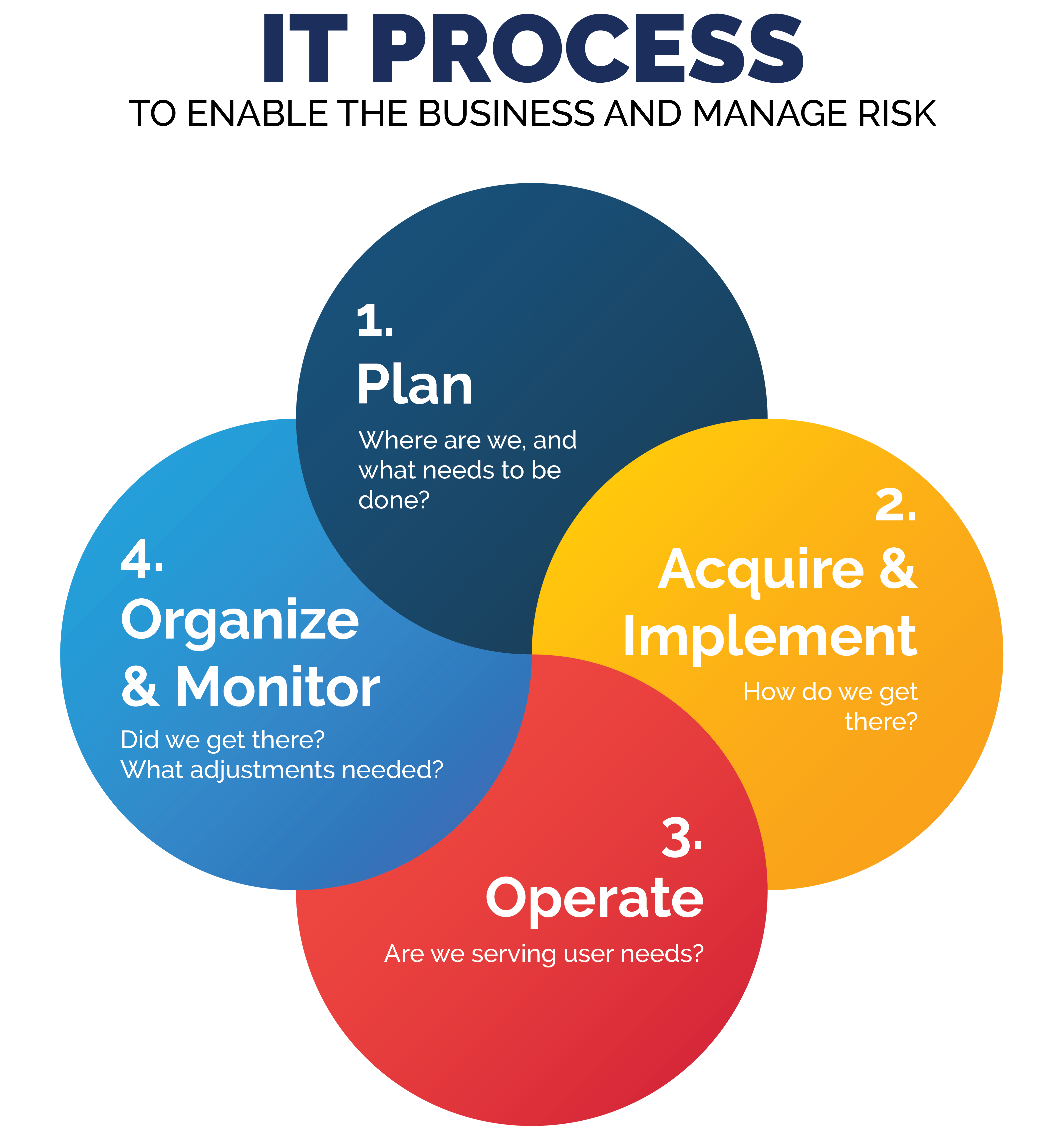
So you planned your new IT process, bought or built what you need , and got it going. If these information and operational technology systems are that important, then they are worth organizing and monitoring to check performance and detect problems. In the last blog of our “IT Process” series, we will focus on organizing and monitoring your Technology Environment and Processes.
Think of this like a car. You figure out what you need; buy it, build it or modify it to suit your needs; and use it to achieve goals. Today, most cars are pretty complex. Repairs and maintenance are best left to trained personnel and specialized equipment. Nonetheless, the driver (you) has a dashboard to help the user keep track of all the different, yet mandatory aspects of maintaining the car. While using the car, a responsible driver also keeps an eye on the road and surrounding areas to navigate traffic and anticipate problems like traffic jams or bad weather. They also check and maintain the overall health of the car by getting it serviced regularly. In this way, the car and the road are monitored, just like IT processes and the IT environment should be!
So how much of this immediate operational monitoring and long-term health check activity is right for your systems? This is important to consider. Too little and problems will not get noticed until too late; too much and it all becomes (costly) noise with a false sense of comfort layered on top.
Not just technology, but people too
Organizing and monitoring the IT (and OT) environment is not just about the systems and data. The IT professionals that operate and secure the systems should be cared for, too. As technology changes and organizations go digital, IT personnel need continuing professional development on new technology, ascending issues and new ways of doing work. This is to ensure they can perform their responsibilities and monitor the multiple third parties that are part of the big picture. And with the shortage of good IT and cybersecurity talent, thinking about the availability and retention of skilled and experienced people makes sense.
Finally, consider the need for independent review of IT activities and controls. Larger organizations may have Internal Audit to do this on a regular basis. If you are a small or medium size entity, perhaps engaging auditors or consultants every year or two to look at higher risk areas of IT can shed new light and bring a fresh perspective, supporting IT management’s assertion that things are OK.
Before monitoring, logging
Most, if not all, applications and infrastructure systems produce a lot of log data by default. Examples of this are records of business transactions, entry adjustments, and approvals; data about the systems activity behind the scenes including processes running and crashes, CPU and disk utilisation, response time, network connections and traffic in and out, which users are active, and so on.
The cost of storage is affordable, so start with standard logging rules for most of these packages or system products. Add more logs to various activities and events based on your critical business processes, related systems, data and infrastructure, as well as regulatory compliance obligations (e.g. payment card transactions, privacy).
These systems usually have their own log files, but most can also send their log records to central log stores in a standard format, such as Syslogs. This is handy for correlation, efficiency and planning. Properly stored log files give you the opportunity to understand the relationships between various systems, see the big picture, and – in the event of a problem like a crash or an intruder – this comprehensive data can help you figure out what happened.
These logs are important, so the logging files and logging functions should be well protected from unauthorized access. It is imperative that the records are not changed or deleted, or the logging is not inadvertently or deliberately stopped (a first step for any experienced hacker to hide their tracks).
Be generous with logging, and judicious with monitoring
What to monitor?
This can be overwhelming, so triage is your friend. Divide and conquer so one person is not drinking out of the figurative fire hydrant. From the sea of log data, determine what data points will help you to ensure important systems are optimized, what is the supporting infrastructure, and what are the compliance requirements. Take the time to design reports so they are good summaries of relevant activities and risks, and highlight important exceptions and matters of concern. This will pay off with reduced time to perform monitoring, and less chance that reports end up getting produced then ignored (until it is too late!)
Monitoring should include both on-premise and cloud service providers. Just like your own business, where you monitor the overall economy, local business environment and suppliers, you should know who your Outsourcers are, and put the same monitoring in place.
Monitoring via reports or on screen is inherently a time-delayed detection mechanism. So once you have the right monitoring of summaries and exceptions being sent to the right people, the next thing is to define what system or user events should be alarmed so IT can be alerted immediately to critical problems. Less is likely better, otherwise the alarms can become noise with serious consequences. Monitoring should include:
- Applications availability and uptime so users and customers are happy;
- Processing failures and errors to keep the systems stable;
- Critical security measures to detect and react to intruders and disruptions timely, for example:
- user password fails,
- user attempts to use functions or see data they do not have access to,
- unusual internet traffic at your gateway and firewall
It also makes sense to monitor some external information concerning the technology system products, both hardware and software, as well as cloud service providers on a regular basis. This will keep you aware of events needing immediate attention, like the Solarwinds network security product compromise and the more recent, and probably more serious, Log4Shell vulnerability which allows the logging mechanisms to be an easy path for hackers into systems that have Java code (ironic that we are talking about logging systems as a risk management tool, and this is now part of the problem!). Less timely but still relevant are events like mergers and acquisitions of your system’s vendors, or notable problems within the vendors, which could mean a decrease in ongoing development of the products or the end of its life.
And so we end up with a monitoring cadence, for example: critical events are alarmed immediately; user or system authentication (password) or authorisation (access to functions or data) fails could be reported daily; systems up-time reported weekly; systems patch status and cloud service provider service levels reported monthly; the age and versions of software and hardware, software license costs and professional development hours of IT personnel reported annually.
After monitoring, act!
Plan – Do – Check – Act is the basis for most good business practices and the same applies to technology in business. The whole purpose of monitoring, just like the dials and warning lights in your car, is to trigger action, like pulling over if your engine overheats. Performance outside accepted parameters should be addressed immediately for critical events (car overheating) and in a timely fashion for less critical ones (gas tank half empty). I was going to use windshield washer fluid low as less critical, but we live in Canada and in the middle of a storm this is important – so perhaps the point is that changes in the environment can make normally less important data and related monitoring more relevant!
Follow up is critical to ensure remedial or corrective actions were performed. Everyone is busy, so assuming it all got done can create a false sense of comfort.
As a by-product of doing this to manage your investment in technology and maintain important business operations, you also end up with evidence of controls to demonstrate compliance to regulatory obligations.
Now that we have concluded the final step in the IT process, you now have the tools to think about how well your current IT and OT meets your business needs for the money spent, and you now have what you need to understand what is going on, at a high level, in the “black box”.











